In natural language processing one of the most important factors that affects the accuracy of any machine learning model or insights you want to gain is the quality of data you provide and how well that data is cleaned.
You might have heard the phrase “garbage in, garbage out” before. This means that if you feed an algorithm with poor-quality data – data that is not properly cleaned, not in the right format and full of unnecessary noise – then the accuracy of your machine learning results will be affected.
There are several steps involved in preparing text data before analysis.
- General Cleaning – This is the first step. It involves organizing the dataset, tidying up the text and removing anything that might cause errors.
- Removing Noise – If the dataset contains information that does not add value and only takes up space we remove it. This results in a smaller cleaner dataset.
- Formatting the Data – The final step ensures that the data is in the right format for the machine learning algorithm we want to use.
Preprocessing our text data changes it from a messy state to a well-structured format. You will see many transformations happening during this process.
In the following sections we will go step by step through each transformation needed to prepare data for further analysis.
Let’s begin our journey into natural language processing.
1. Lowercase
Lowercasing helps maintain consistency in our data and outputs.
When working with text – whether for exploratory analysis or machine learning – we want to ensure that words are recognized and counted as the same word. Without lowercasing your model might treat a word with a capital letter differently from the same word in lowercase.
By converting text to lowercase we ensure uniformity, making it easier to clean and process the data. This way we don’t have to handle multiple cases separately.
However, keep in mind that lowercasing can sometimes change the meaning of a word. For example, “US” in capital letters refers to a country, whereas “us” in lowercase simply means “we”.
How to Convert Text to Lowercase in Python
It is very easy to convert text into lowercase using Python’s built-in .lower() function.
Let’s take an example:
We have the sentence:
“Her cat’s name is Luna.”
To convert it into lowercase, we simply run:
sentence = "Her cat's name is Luna."
lowercase_sentence = sentence.lower()
print(lowercase_sentence)
This will output:
“her cat’s name is luna.”
We can also apply this function to a list of sentences.
For example, if we have a list of three different sentences we can convert all of them into lowercase like this:
sentence_list = ["This is a Cat.", "Python is FUN!", "HELLO World!"]
lower_sentence_list = [x.lower() for x in sentence_list]
print(lower_sentence_list)The output will be:
[‘this is a cat.’, ‘python is fun!’, ‘hello world!’]
As you can see, everything in our list has been successfully converted to lowercase.
2. Removing Stopwords
In this section, we will use the NLTK package to remove stopwords from our text.
What Are Stopwords?
Stopwords are common words in a language that don’t carry much meaning.
For example, words like “and”, “of”, “a” and “to” are considered stopwords.
We remove these words because they add unnecessary complexity to our data. Since they don’t contribute much meaning, removing them helps create a smaller and cleaner dataset.
A smaller, cleaner dataset often leads to:
– Increased accuracy in machine learning
– Faster processing times
Steps to Remove Stopwords
- Import the Required Packages
First, we need to import the NLTK package and download the stopwords list.
If you haven’t downloaded them before, it may take a few minutes to install. Once downloaded, you can simply import them. - Load the Stopwords List
We’ll assign the English stopwords to a variable called stop_words since we’ll be using the English language.
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
en_stopwords = stopwords.words('english')
print(en_stopwords)Printing the stopwords list will show a collection of small, common words that don’t add much meaning to a sentence.
Removing Stopwords from a Sentence
Let’s take an example sentence:sentence = "it was too far to go to the shop and he did not want her to walk."
We will remove the stopwords using Python.
sentence_no_stopwords = ' '.join([word for word in sentence.split() if word not in en_stopwords])
print(sentence_no_stopwords)Output:
“far go shop want walk”
Here, only the meaningful words are kept, while common words like “it,” “was,” “to,” “the,” and “and” have been removed.
Customizing the Stopwords List
Sometimes, you might want to add or remove specific words from the stopwords list.
- Removing a Word from Stopwords
If you want to keep certain words that are in the default stopwords list, you can remove them using.remove().en_stopwords.remove('did')
en_stopwords.remove('not') - Adding a Word to Stopwords
If you want to add extra words to the stopwords list, you can use.append().en_stopwords.add('go')
After modifying the stopwords list, we can re-run our sentence filtering and see the updated results.
sentence_no_stopwords_custom = ' '.join([word for word in sentence.split() if word not in en_stopwords])
print(sentence_no_stopwords_custom)Updated Output:
“far shop did not want walk”
By customizing our stopwords list, we capture the sentence’s meaning better while still removing unnecessary words.
3. Regular Expressions
Regular expressions, or regex, is a special syntax used for searching and matching patterns in text.
Instead of searching for hardcoded words or phrases, regex allows us to filter and sort text based on patterns. This makes it a powerful tool for text processing.
Since there are many different regex options and rules, the best way to learn is by jumping into some examples.
Using the re Package in Python
To start working with regex in Python, we first need to import the re package.
import re
Before we start writing regex code, let’s cover an important concept: raw strings.
Understanding Raw Strings in Python
Python treats certain characters as special symbols.
For example, \n represents a new line. However, sometimes we want Python to treat these symbols as plain text instead of their special meaning.
We can do this using raw strings by adding an r before the string.
Let’s illustrate this with a file path example:
folder_path = "C:\desktop\notes"
print(folder_path)Here, \n was interpreted as a new line, breaking our text.
Now, let’s add an r before the string:
folder_path = r"C:\desktop\notes"
print(folder_path)Now, the backslash is treated as part of the string, which is important when working with regex, as it often uses special characters.
Regex Functions in Python
re.search()– Finding a Pattern in a String
There.search()function checks if a pattern exists in a string.result_search = re.search("apple", r'I like apple pie.')
result_search_2 = re.search("apple", r'I like orange pie.')If the pattern exists in the text,
re.search()returns a match. Otherwise, it returnsNone.re.sub()– Replacing Text with Regex
There.sub()function allows us to find and replace text in a string.string = r"sara was able to help me find the items I needed quickly."
updated_text = re.sub("Sara", "Sarah", string)
print(updated_text)Here,
re.sub()found “Sara” and replaced it with “Sarah”.
Advanced Regex Patterns
- Finding Text with Different Spellings
Let’s say we want to find reviews mentioning “Sarah”, but we also want to match the incorrect spelling “Sara”.We can use the question mark (
?) operator, which makes the preceding character optional.customer_reviews = [ "Sara was very helpful!", "Sarah did a great job.", "John was excellent!" ]sarahs_reviews = []pattern_to_find = r"sarah?"for string in customer_reviews:
if (re.search(pattern_to_find, string)):
sarahs_reviews.append(string)
print(sarahs_reviews)Output:
["Sara was very helpful!", "Sarah did a great job."]Now, both “Sara” and “Sarah” are matched!
- Finding Text That Starts with a Specific Letter
To find reviews that start with “A”, we use the^caret operator, which represents the start of a string.pattern = r"^A"
customer_reviews = [
"Amazing work from Sarah!",
"Great support from the team!",
"All issues were resolved."
]
a_reviews = []
for review in customer_reviews:
if (re.search(pattern, review)):
a_reviews.append(review)
print(a_reviews)Output:
["Amazing work from Sarah!"] - Finding Text That Ends with a Specific Letter
To find reviews ending with “y”, we use the dollar sign ($), which represents the end of a string.pattern = r"y$"
customer_reviews = [
"Amazing work from Sarah!",
"Great support from the team!",
"All issues were resolved.",
"Sarah was very friendly.",
"Amazing experience!",
"The support team was helpful."
]
y_reviews = []
for review in customer_reviews:
if (re.search(pattern, review)):
y_reviews.append(review)
print(y_reviews)Output:
["Sarah was very friendly."] - Finding Multiple Words with the
|(Pipe) Operator
Let’s find reviews that contain either “needed” or “wanted”.pattern = r"(need|want)ed"
customer_reviews = [
"Amazing work from Sarah!",
"Great support from the team!",
"All issues were resolved.",
"Sarah was very friendly.",
"Amazing experience!",
"The support team was helpful.",
"I needed quick assistance.",
"She wanted to help.",
"Great customer service!"
]
reviews = []
for review in customer_reviews:
if (re.search(pattern, review)):
reviews.append(review)
print(reviews)Output:
["I needed quick assistance.", "She wanted to help."]The pipe (|) operator works like “OR”, allowing us to search for multiple words at once.
- Removing Punctuation with Regex
One of the most common tasks in Natural Language Processing (NLP) is removing punctuation. To do this, we use there.sub()function with a pattern that removes everything except words and spaces.pattern = r"[^\w\s]"
customer_reviews = [
"Sarah was great!",
"Amazing experience!!!",
"Excellent, fast service."
]
reviews = []
no_punct_string = ""
for review in customer_reviews:
if (re.search(pattern, review)):
no_punct_string = re.sub(pattern, '', review)
reviews.append(no_punct_string)
print(reviews)Output:
["Sarah was great", "Amazing experience", "Excellent fast service."]Here’s how it works:
[]– Defines a character set.^– Means “not”.\w– Matches letters, numbers, and underscores.\s– Matches spaces.[^\w\s]– Matches everything except words and spaces (i.e., punctuation).
4. Tokenization
A fundamental step in Natural Language Processing (NLP) is tokenization which involves breaking text into smaller units called tokens.
The most common type of tokenization is word tokenization where each individual word in a sentence becomes a token. But, tokens can also be sentences, subwords or even individual characters, depending on the use case.
We tokenize text because understanding individual parts helps us better analyze the meaning of the whole text. It is also an important preprocessing step before we can factorize our data.
We will use the NLTK package to perform sentence tokenization and word tokenization.
Importing Required Libraries
First, we need to import NLTK and download the necessary resources.import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize, sent_tokenize
Sentence Tokenization
Sentence tokenization breaks a paragraph into individual sentences.
Let’s take an example:sentences = "Her cat's name is Luna. Her dog's name is Max."
sentences = sent_tokenize(sentences)
print(sentences)
Output:["Her cat's name is Luna.", "Her dog's name is Max."]
Here, our text is correctly split into two sentences.
Word Tokenization
Now, let’s break a sentence into individual words.sentence = "Her cat's name is Luna."
words = word_tokenize(sentence)
print(words)
Output:["Her", "cat", "'s", "name", "is", "Luna", "."]
Each word (including punctuation) is treated as a separate token.
Tokenizing a Longer Sentence
Let’s try word tokenization on a longer sentence.text = "Her cat's name is Luna. Her dog's name is Max."
tokens = word_tokenize(text)
print(tokens)
Output:["Her", "cat", "'s", "name", "is", "Luna", ".", "Her", "dog", "'s", "name", "is", "Max", "."]
Why Lowercasing Is Important in Tokenization
Notice that “Her” appears twice:
– “Her” (uppercase H)
– “her” (lowercase h)
Since these are treated as different tokens, it can affect tasks like word frequency counting in NLP.
To avoid this issue, we convert text to lowercase before tokenization.lower_text = text.lower()
tokens_lower = word_tokenize(lower_text)
print(tokens_lower)
Output:["her", "cat", "'s", "name", "is", "luna", ".", "her", "dog", "'s", "name", "is", "max", "."]
Now, both instances of “her” are treated as the same token, ensuring consistency in the data.
5. Stemming
The next step in preprocessing is to standardize the text. One way to do this is stemming which reduces words to their base form.
For example:
– “connecting” = “connect”
– “connected” = “connect”
How does stemming work?
Stemming removes the suffix (ending) of a word but sometimes the result is not a proper word.
We use stemming because it reduces the number of unique words and making our dataset smaller and less complex. Removing complexity and noise is a key step in preparing data for machine learning.
Using the Porter Stemmer in Python
We will use NLTK’s Porter Stemmer to perform stemming.
Importing the Required Libraryfrom nltk.stem import PorterStemmer
We then create a stemmer object:ps = PorterStemmer()
Example 1: Stemming Words Related to “Connect”
Let’s apply stemming to words related to “connect”:words = ["connecting", "connected", "connectivity", "connect", "connects"]
for word in words:
print(word, ": ", ps.stem(word))
Output:
connecting: connect
connected: connect
connectivity: connect
connect: connect
connects: connect
Here, all words have been reduced to “connect”, ensuring consistency in our dataset.
Example 2: Stemming Words Related to “Learn”
Now, let’s try the same process for words related to “learn”:words = ["learned", "learning", "learn", "learns", "learner", "learners"]
for word in words:
print(word, ": ", ps.stem(word))
Output:
learned: learn
learning: learn
learn: learn
learns: learn
learner: learner
learners: learner
Most words were reduced to “learn”, but “learner” and “learners” were stemmed differently. This happens because stemming does not always produce a proper word.
Example 3: Stemming Words Like “Likes”, “Better”, and “Worse”
Let’s see how stemming affects words with irregular forms:words = ["likes", "better", "worse"]
for word in words:
print(word, ": ", ps.stem(word))
Output:
likes: like
better: better
worse: wors
Here we noticed:
“likes” was correctly stemmed to “like”
“better” remained unchanged
“worse” was incorrectly stemmed to “wors” (not a proper word)
This shows one of the limitations of stemming, it sometimes creates words that don’t make sense.
6. Lemmatization
Unlike stemming which removes the last few characters of a word, lemmatization reduces a word to its meaningful base form without losing its meaning.
Lemmatization is more intelligent because it references a predefined dictionary that understands the context of a word. This ensures that the word’s root form is meaningful.
– Lemmatization produces more accurate words
– It keeps the original meaning intact
– It does not always reduce words to a single token
But words are not aggressively reduced, lemmatization results in a larger dataset compared to stemming.
Using Lemmatization in Python
Importing Required Librariesimport nltk
nltk.download('wordnet')
from nltk.stem import WordNetLemmatizer
Next, we create our lemmatizer object:lemmatizer = WordNetLemmatizer()
Example 1: Lemmatizing “Connect” Tokens
Let’s apply lemmatization to words related to “connect”:
words = ["connecting", "connected", "connectivity", "connect", "connects"]
for word in words:
print(word, ": ", lemmatizer.lemmatize(word))
Output:
connecting: connecting
connected: connected
connectivity: connectivity
connect: connect
connects: connects
Unlike stemming, which reduced all words to “connect”, lemmatization keeps the original words intact.
This preserves the meaning but results in a larger dataset because words are not merged into a single token.
Example 2: Lemmatizing “Learn” Tokens
Let’s try lemmatization on words related to “learn”:
words = ["learned", "learning", "learn", "learns", "learner", "learners"]
for word in words:
print(word, ": ", lemmatizer.lemmatize(word))
Output:
learned: learned
learning: learning
learn: learn
learns: learns
learner: learner
learners: learner
The only word that changed is “learners” to “learner”.
Everything else remains the same, unlike stemming, which aggressively reduced words to “learn”.
Example 3: Lemmatizing “Likes, Better, and Worse”
Let’s compare how lemmatization handles words with irregular forms:
words = ["likes", "better", "worse"]
for word in words:
print(word, ": ", lemmatizer.lemmatize(word))
Output:
likes: like
better: better
worse: worse
– “likes” was reduced to “like”
– “better” remained unchanged
– “worse” correctly remained “worse”
This is different from stemming, where “worse” was incorrectly reduced to “wors” (not a real word).
Key Differences Between Stemming and Lemmatization
| Stemming | Lemmatization | |
| How it works? | Removes word endings | Uses a dictionary to find the base form |
| Accuracy | Can create non-words (e.g., “wors”) | Keeps words meaningful |
| Dataset size | Produces fewer unique words | Produces more unique words |
| Examples | connected to connect worse to wors |
connected to connected worse to worse |
7. N-Grams
A useful way to analyze and explore text is by breaking it into n-grams.
– N-grams are sequences of n neighboring words or tokens.
– This helps us check preprocessing, explore the contents of our data and create new features for machine learning.
The value of n determines how many words appear in each sequence:
Unigrams (n = 1) = Single words
Bigrams (n = 2) = Pairs of words
Trigrams (n = 3) = Groups of three words
N-grams (n > 3) = General term for larger sequences
Using N-Grams in Python
To work with n-grams, we need to import three libraries:
import nltk
import pandas as pd
import matplotlib.pyplot as plt
Creating Tokens for Analysis
For this example, let’s create some sample tokens.
tokens = ['the', 'rise', 'of', 'artificial', 'intelligence', 'has', 'led', 'to', 'significant', 'advancements', 'in', 'natural', 'language', 'processing', 'computer', 'vision', 'and', 'other', 'fields', 'machine', 'learning', 'algorithms', 'are', 'becoming', 'more', 'sophisticated', 'enabling', 'computers', 'to', 'perform', 'complex', 'tasks', 'that', 'were', 'once', 'thought', 'to', 'be', 'the', 'exclusive', 'domain', 'of', 'humans', 'with', 'the', 'advent', 'of', 'deep', 'learning', 'neural', 'networks', 'have', 'become', 'even', 'more', 'powerful', 'capable', 'of', 'processing', 'vast', 'amounts', 'of', 'data', 'and', 'learning', 'from', 'it', 'in', 'ways', 'that', 'were', 'not', 'possible', 'before', 'as', 'a', 'result', 'ai', 'is', 'increasingly', 'being', 'used', 'in', 'a', 'wide', 'range', 'of', 'industries', 'from', 'healthcare', 'to', 'finance', 'to', 'transportation', 'and', 'its', 'impact', 'is', 'only', 'set', 'to', 'grow', 'in', 'the', 'years', 'to', 'come']
These tokens have not been fully preprocessed.
Now, let’s check the unigrams in our data.
Unigrams (n = 1)
A unigram refers to single words in the dataset.
We will use Pandas and NLTK to compute the frequency of each unigram:
unigrams = (pd.Series(nltk.ngrams(tokens, 1)).value_counts())
print(unigrams)
This will output the most common unigrams in our dataset.
For example, if our dataset contained repeated words, the output might look like this:
Output:(to,) 7
(of,) 6
(the,) 4
(in,) 4
(learning,) 3
(and,) 3
(more,) 2
(that,) 2
(from,) 2
(processing,) 2
This helps us see which words appear most often.
Visualizing Unigrams with a Bar Chart
To make this more useful for stakeholders or presentations, we can visualize the top 10 unigrams using a horizontal bar chart.
unigrams[:10].sort_values().plot.barh(color="lightsalmon", width=.9, figsize=(12,8))
plt.title("10 most frequently occuring unigrams")
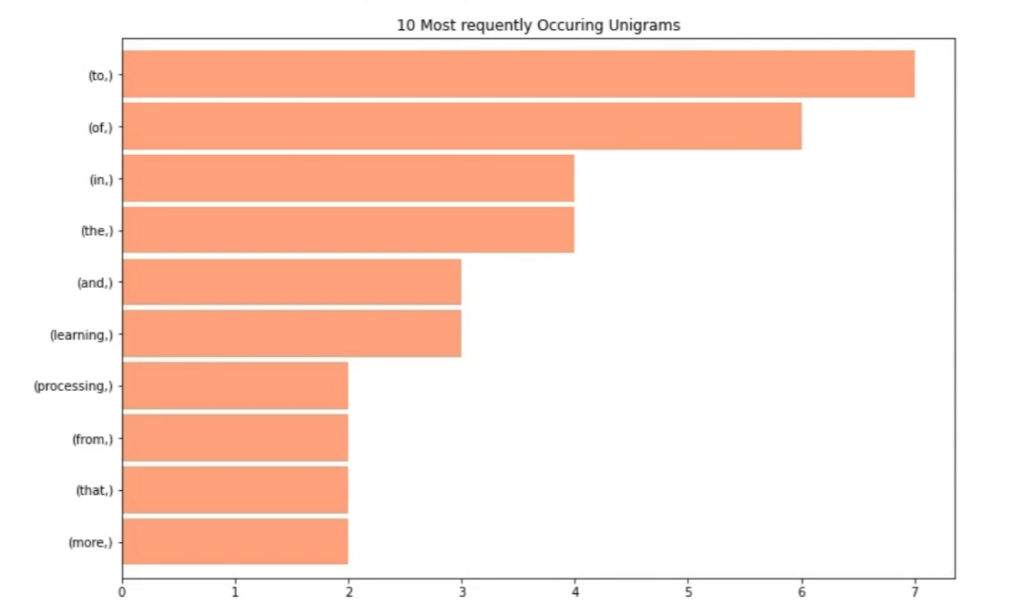
This creates a clear, visually appealing chart showing the most frequent unigrams in the dataset.
Bigrams (n = 2)
A bigram consists of two-word pairs appearing together.
We use the same approach but change n = 2:
unigrams = (pd.Series(nltk.ngrams(tokens, 2)).value_counts())
print(unigrams)
Output:(that, were) 2
(is, increasingly) 1
(of, industries) 1
(intelligence, has) 1
(from, healthcare) 1
(neural, networks) 1
(before, as) 1
(in, a) 1
(the, years) 1
(advancements, in) 1
Since bigrams represent word pairs, they help us understand common word relationships in text.
If many words only appear once, we might not need to plot them. But, for larger datasets, bigrams can reveal meaningful patterns.
Trigrams (n = 3)
A trigram consists of three-word sequences.
unigrams = (pd.Series(nltk.ngrams(tokens, 3)).value_counts())
print(unigrams)
Output:(that, were) 2
(is, increasingly) 1
(of, industries) 1
(intelligence, has) 1
(from, healthcare) 1
(neural, networks) 1
(before, as) 1
(in, a) 1
(the, years) 1
(advancements, in) 1
Again, if trigrams appear only once, we don’t need to visualize them. But for larger datasets, they help identify frequent phrases.
N-Grams (n > 3)
For n > 3, we refer to them as n-grams.
For example, n = 4 means four-word sequences, n = 5 means five-word sequences, and so on.
N-grams beyond trigrams are mostly used in advanced NLP tasks, such as text generation and machine translation.