We talk so many times about making a highly performant and highly scalable system, caching is probably will be a part of the solution. Hitting disk is really expensive and you want to avoid hitting discs in your database or whatever data store you have as much as possible. And one way to do that is caching the database information in memory, inside a cache of some sort.
Uncached Architecture
We will start with sort of an uncached architecture here, one that just hits the database directly.
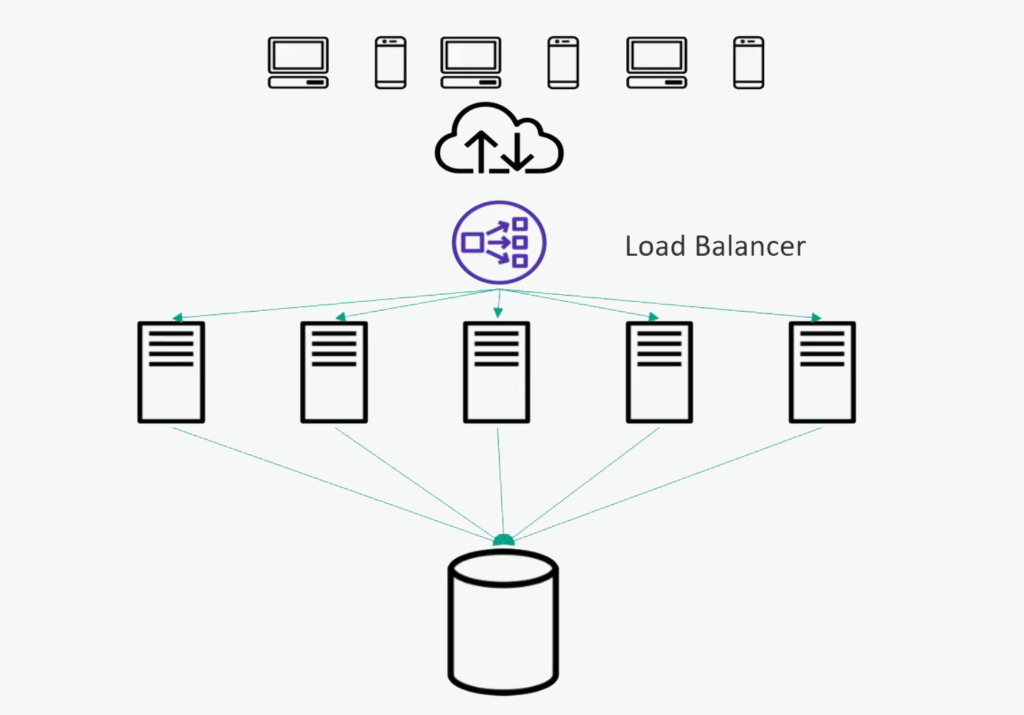
To review here, we have our clients at the top, communicating through the internet, talking to a load balancer. That might be a hardware device or software running on a service fleet of its own. But basically, that load balancer is distributing that traffic to a horizontally distributed fleet of application servers or web servers, depending on what you are doing.
Now in the diagram, they are all talking to one big database, so there is a big bottleneck. If I will be hitting the disc from all of those distributed app servers, that could bring the database down. I have only got so many hard drives and so many disc heads, they can only do so much at once. So those disc kits will be expensive.
Usually, the database will have its own caching internally inside the database itself. But that might not be enough. There is only so much memory you can put on one host. And even if that is the distributed database system, it would be beneficial to have a cache closer to the application hosts themselves.
Adding a Caching Layer
The way, or one way to deal with that, is by introducing a caching layer. That is probably a fleet of other servers that are sitting alongside your application servers, whose only job is to keep in-memory copies of data that is going to that database.
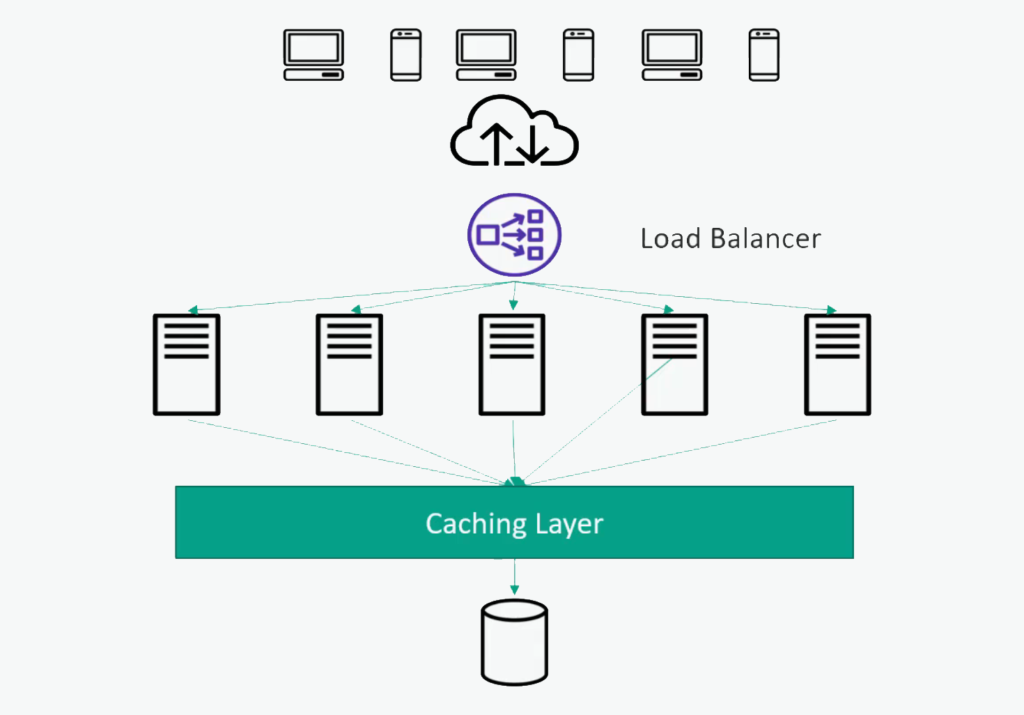
So it can keep track of the most recent hits to the database or the most popular ones and keep that cached in memory, which will be a lot faster to access than hitting the disc in your big bottleneck database there. Another advantage of that is that we can actually scale that caching fleet independently of our application fleet if we want to.
One would be to actually have the caches built into the application servers themselves. That is a simpler way of doing it, but it can be beneficial to have your own separate fleet of caching servers.
You can actually scale that independently of the application hosts. That way, if you want to minimize the load on your database even further, you can throw more hosts at your caching layer instead.
How Caches Work
Like I said, it is usually a horizontally scaled fleet of some sort, and there are off-the-shelf solutions for this. Of course, you don’t have to rewrite caching servers by yourself from scratch. You can just go get one that works.
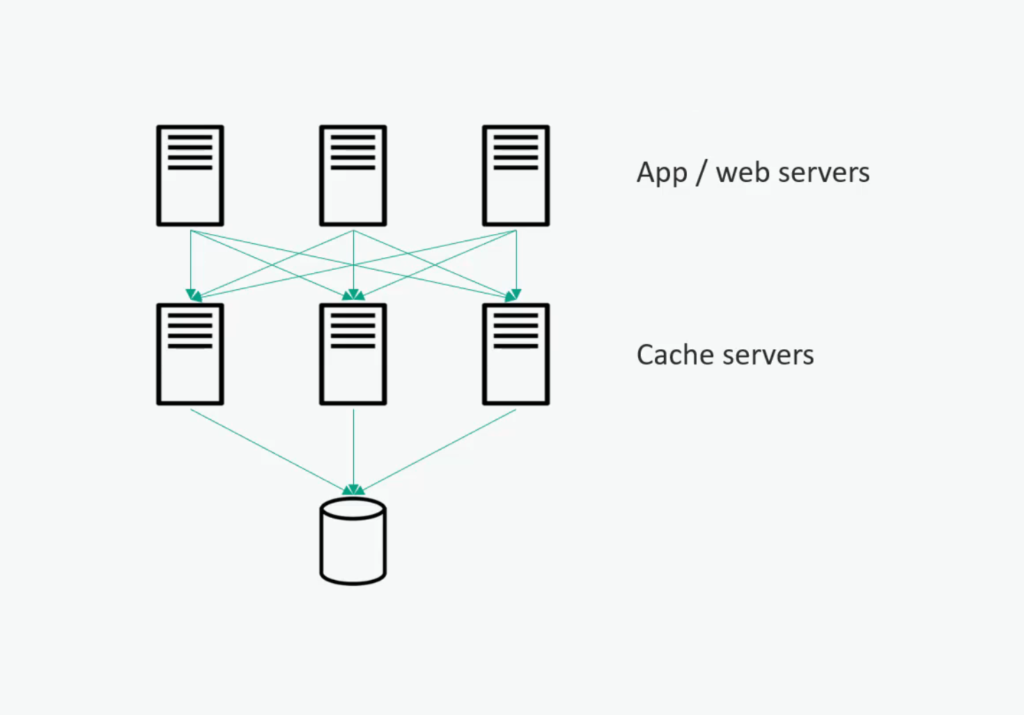
Fundamentally, the clients, which will be your web servers or application servers, will hash a request for a database call to some given server. So it will apply some mathematical function to the key you are looking for and say, “Okay, for this key, I know I want to go to this caching host,” and that caching host will be responsible for that little segment of the data there.
So that is the way to distribute the information amongst that entire fleet of cache servers. Basically, every cache server is responsible for some subset of the data in the database underneath it.
And that hash function allows us to quickly map which server we need to talk to. Of course, there might be redundancy there too, but we are not going to get into those implementation details here.
Read-Heavy Applications
Because that is in-memory, it is very fast and it might also be local to where the application servers are physically to make it even faster.
This is very appropriate for applications that have more reads than writes and that is usually the case. Most applications you can think of hitting a Wikipedia or something like that, or an e-commerce website, you are retrieving information more than writing information.
Whenever I write information, that will invalidate my cache for that data. So if I am doing a lot of writes, the cache will not do as much good because every time I write something, I have to invalidate the cached copy of that data at the same time. But if I am doing more reads than writes, then yes, a cache can help a lot.
Cache Expiration Policy
Now we need to think about the expiration policy of our cache that will dictate how long data is cached for. That involves thinking about your application and your requirements. How long can I hang onto this data without it being considered stale?
If it is too long, your data might be out of date and stale, and that might not be acceptable at all. There might be applications like, in banking where caching is not acceptable. You always need to have consistent data coming back, no matter what.
But if it is too short, then your cache will not do any good. If you are only caching the past second of data, that might not be a whole lot of data. So that might not be as effective.
A smart cache will be intelligent about monitoring what gets written and updated and invalidating cache entries as you go. So the staleness might not actually be a concern in that case. But still, you need to think about how long you might want to keep it for before you start to worry about it being out of date.
Challenges in Caching
Hotspots Problem
Imagine you are managing a database like IMDb. You might store information about different actors on separate cache servers. For example, one server might handle a lesser-known actor, while another handles someone super popular like TheOne. The problem is that everyone searches for TheOne, so the server hosting this data gets overloaded with traffic.
This is what we call a hotspot. A smarter caching system would not just use a simple method to assign data based on a key. Instead, it would monitor traffic patterns and handle the load more intelligently. For instance, it might dedicate a server just for TheOne’s data or spread his data across multiple servers to balance the load.
Hotspots can be a significant issue, and solving them might involve discussing solutions during application design.
Cold-Start Problem
A common issue in caching is the cold-start problem. If your system relies heavily on caching to function, it can face serious trouble when the caching layer is first turned on or needs to restart. When the cache is empty, every request hits the database until the cache is filled. This can overwhelm the database, especially if the traffic is heavy, potentially causing it to crash.
To address this, you need a strategy to handle the cold-start problem. One solution is to warm up the cache before making it available to users. This can involve sending simulated traffic to the cache, such as replaying data from the previous day, to pre-load it. Only make the system live once the cache is fully prepared to handle real traffic. This approach helps prevent overloading the database during the initial stages.
Outline
Here are some outlines from the blog.
- Horizontally distributed caches are a good thing.
- If you have more reads than writes, caching is highly effective.
- Think about your expiration policy, don’t make it too short or too long.
- Address hotspots and the cold-start problem to avoid performance issues.
By addressing these considerations, you can build a highly performant and scalable system using caching technologies.